Agents drift.
Before your users do.
The behavioral verification layer your observability stack is missing.
Fingerprint execution shape — tools, call graphs, errorstool sequences, call graphs, error patterns
Block regressions before merge — gate every PRpolicy-gated on every PR
Privacy-safe by default — structure only, no contentcaptures execution structure, never prompts or responses
Drift comes in quiet.
We catch it loud.
Behavioral verification for AI agents · 49 seconds
Every agent. Every run.
One view.
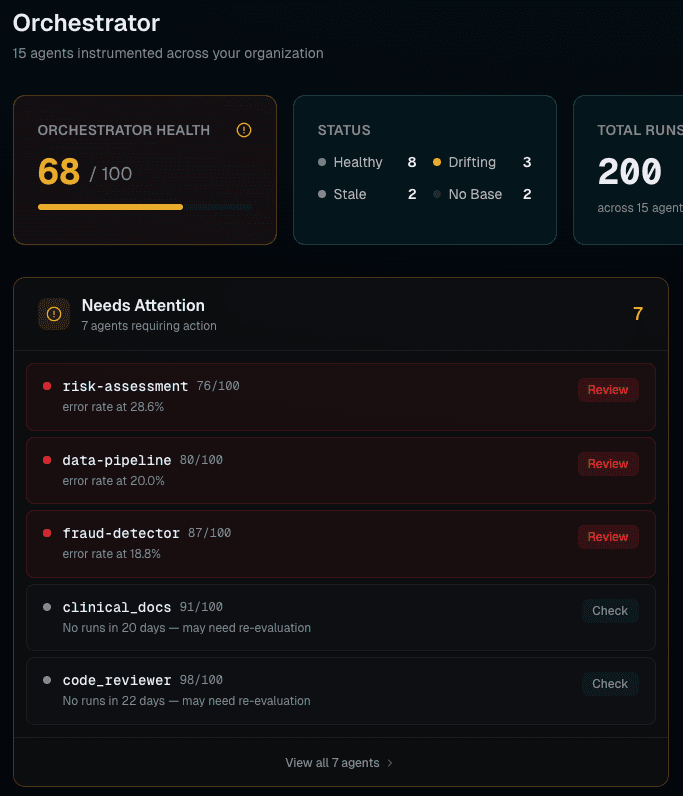
Fleet-wide visibility
Health scores, drift status, and error rates — every agent, one screen.
Included with Pro · Hosted at app.spooled.ai
Same code. Different behavior.
We catch behavioral drift.
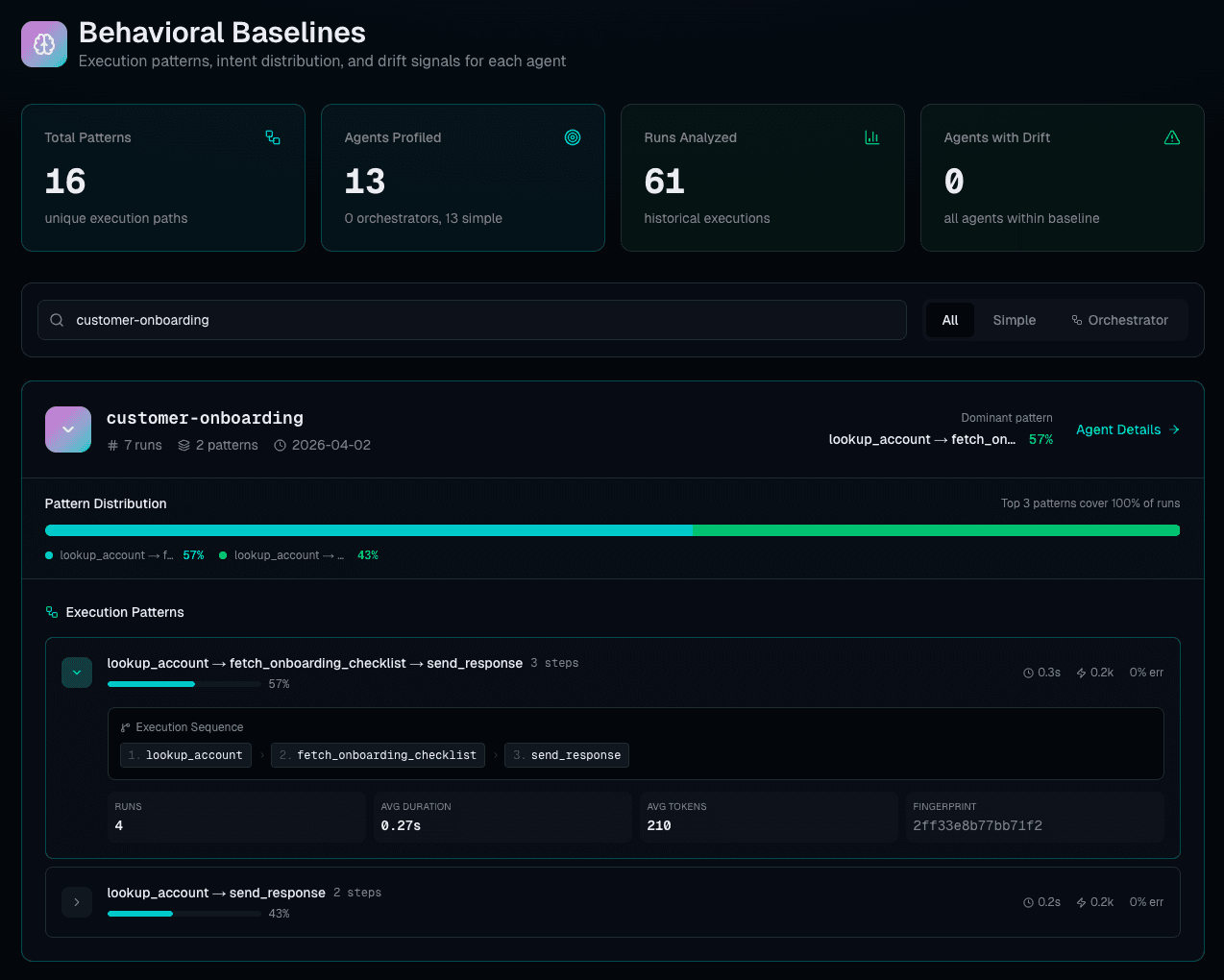
Behavioral fingerprinting
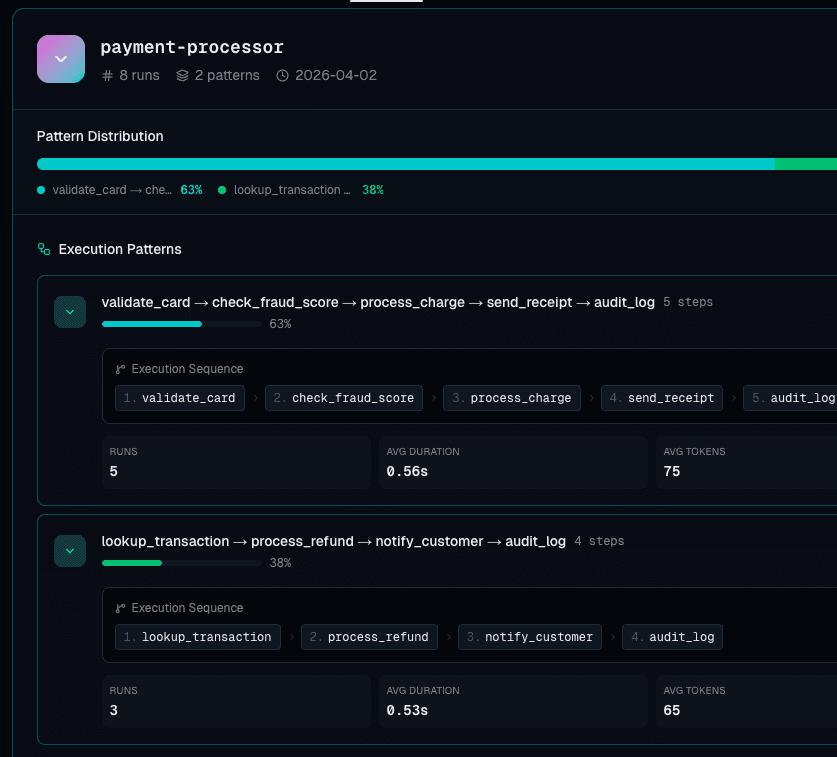
Every agent run produces a structural fingerprint from its execution shape — which tools ran, in what order, how many times. We diff it three ways — tool set, call sequence, and error pattern — to catch drift that output evals miss.
Learn more →Built-in drift signals
Latency spikes, tool changes, retry explosions, token usage spikes, schema drift — detected automatically. Zero assertions to write.
Learn more →Privacy-safe by default
Spooled analyzes execution structure, not call content. Prompts, responses, and tool payloads are stripped at the SDK level before storage. We publish a threat model with every defended claim linked to a reproducible test fixture.
Learn more →CI-native
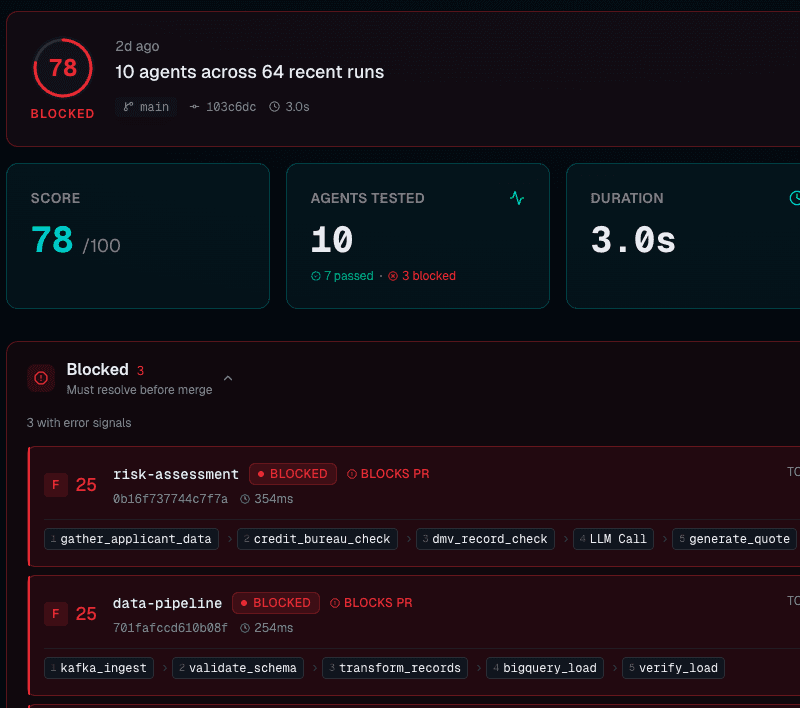
GitHub Action drops into your pipeline. Policy YAML gates merges. Every PR gets a behavioral diff, inline signal annotations, and a Spooled Score.
Learn more →Three steps. Zero assertions.
One line instruments your agent. Spooled captures tool sequences, timing, and decision patterns — not content.
import spooled from spooled.wrappers import ( wrap_openai, ) spooled.init(agent_id="agent") client = wrap_openai(OpenAI())
See how stable your agent actually is. Which tools fire every time and which are flaky.
$ spooled analyze --agent-id agent Runs: 10 Graphs: 3 / 10 Stable: yes Tool Reliability search_deals ●●●●● 100% check_sanctions ●●●●● 100% price_model ●●○●● 90% send_summary ●○●○● 70%
Run in CI on every PR. Spooled compares execution shapes, scores behavior, and blocks regressions.
$ spooled ci run \ --suite tests/agents/ ┌── agent ───── PASS ────┐ │ Fingerprint: MATCH │ │ Score: 94/100 (A) │ │ Tokens: 1,204 (-0.2%) │ │ Signals: none │ │ Policy: PASSED │ └────────────────────────┘
Other tools watch what your agent said.
We watch what it did.
Spooled
Observability tools
The kind of drift Spooled catches.
Sanctions check silently dropped
API schema renamed a field. Agent stopped detecting international operations. Still recommended 'proceed' on a sanctioned entity. Spooled caught it.
Customer response vanished
KB refresh added a fraud policy. Agent started escalating fraud tickets without sending the acknowledgment response. Customers got silence.
Approval rate drifted +10pp
One 'reduce friction' prompt note shifted the portfolio from 30% to 40% approvals. Every individual decision was defensible. The aggregate wasn't.
Retry path appeared
Primary provider went flaky. Agent retried and succeeded — but the retry path was a new fingerprint. Spooled named the shift before latency metrics noticed.
One price. Everything included.
Free is fully featured locally. Pro adds production observability, dashboards, and team collaboration.
Privacy-safe by default · Cancel anytime · No partial-month refunds
Free Plan
Full-featured locally. No credit card, no backend required.
- ✓Unlimited agents and traces
- ✓Behavioral fingerprinting and diffing
- ✓Baselines, policy engine, merge blocking
- ✓Full PR comments and GitHub annotations
- ✓Hash chain verification
- ✓All local CLI commands
Pro
$99/monthProduction observability. Dashboard, alerts, audit trail, team access.
- ✓Everything in Free
- ✓Backend trace ingest from staging/production
- ✓Hosted dashboard with fleet view
- ✓Drift detection on every trace
- ✓Webhook drift alerts (Slack-compatible)
- ✓Audit log with 90-day retention
- ✓Up to 10 API keys
Larger team? hello@spooled.ai